
艾锑知识 |什么是网络爬虫
2020-02-17 12:50 作者:艾锑无限 浏览量:
迎战疫情,艾锑无限用爱与您同行
为中国中小企业提供免费IT外包服务

为中国中小企业提供免费IT外包服务
这次的肺炎疫情对中国的中小企业将会是沉重的打击,据钉钉和微信两个办公平台数据统计现有2亿左右的人在家远程办公,那么对于中小企业的员工来说不懂IT技术将会让他们面临的最大挑战和困难。
电脑不亮了怎么办?系统蓝屏如何处理?办公室的电脑在家如何连接?网络应该如何设置?VPN如何搭建?数据如何对接?服务器如何登录?数据安全如何保证?数据如何存储?视频会议如何搭建?业务系统如何开启等等一系列的问题,都会困扰着并非技术出身的您。

好消息是当您看到这篇文章的时候,就不用再为上述的问题而苦恼,您只需拨打艾锑无限的全国免费热线电话:400 650 7820,就会有我们的远程工程师为您解决遇到的问题,他们可以远程帮您处理遇到的一些IT技术难题。
如遇到免费热线占线,您还可以拨打我们的24小时值班经理电话:15601064618或技术经理的电话:13041036957,我们会在第一时间接听您的来电,为您提供适合的解决方案,让您无论在家还是在企业都能无忧办公。
那艾锑无限具体能为您的企业提供哪些服务呢?

第一版块是保障性IT外包服务:如电脑设备运维,办公设备运维,网络设备运维,服务器运维等综合性企业IT设备运维服务。
第二版块是功能性互联网外包服务:如网站开发外包,小程序开发外包,APP开发外包,电商平台开发外包,业务系统的开发外包和后期的运维外包服务。
第三版块是增值性云服务外包:如企业邮箱上云,企业网站上云,企业存储上云,企业APP小程序上云,企业业务系统上云,阿里云产品等后续的云运维外包服务。
您要了解更多服务也可以登录艾锑无限的官网:www.bjitwx.com查看详细说明,在疫情期间,您企业遇到的任何困境只要找到艾锑无限,能免费为您提供服务的我们绝不收一分钱,我们全体艾锑人承诺此活动直到中国疫情结束,我们将这次活动称为——春雷行动。
以下还有我们为您提供的一些技术资讯,以便可以帮助您更好的了解相关的IT知识,帮您渡过疫情中办公遇到的困难和挑战,艾锑无限愿和中国中小企业一起共进退,因为我们相信万物同体,能量合一,只要我们一起齐心协力,一定会成功。再一次祝福您和您的企业,战胜疫情,您和您的企业一定行。
艾锑知识 |什么是网络爬虫
互联网诞生之初,是为了让人们更容易的分享数据、交流通讯。互联网是桥梁,连接了世界各地的人们。网站的点击、浏览都是人为的,与你聊天的也是活生生的人。然而,随着技术的发展,人们对数据的渴望,出现了各种网络机器人,这个时候,你不知道屏幕那端跟你聊天的是一个人还是一条狗,你也不知道你网站的浏览量是人点击出来的,还是机器爬出来的。表面上看,互联网上是各种各样的人;暗地里,已
经布满了形形色色的网络爬虫。

一、搜索引擎时代的网络爬虫
关于网络爬虫的概念,我们先来瞅瞅维基百科(Wikipedia)上面的定义:
网络爬虫(英语:web crawler),也叫网上蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。这里提到的编纂网络索引,就是搜索引擎干的事情。我们对搜索引擎并不陌
生,Google、百度等搜索引擎可能每天都在帮我们快速获得信息。可能小猿们要问,搜索引擎的工作过程是怎样的呢?
首先,就是有网络爬虫不断抓取各个网站的网页,存放到搜索引擎的数据库;
接着,索引程序读取数据库的网页进行清理,建立倒排索引;
最后,搜索程序接收用户的查询关键词,去索引里面找到相关内容,并通过一定的排序算法(Pagerank等)把最相关最好的结果排在最前面呈现给用户。
看上去简简单单的三个部分,却构成了强大复杂的搜索引擎系统。而网络爬虫是其中最基础也很重要的一部分,它决定着搜索引擎数据的完整性和丰富性。我们也看到网络爬虫的主要作用是获取数据。由此简单
地说,网络爬虫就是获取互联网公开数据的自动化工具。这里要强调一下,网络爬虫爬取的是互联网上的公开数据,而不是通过特殊技术非法入侵到网站服务器获取的非公开数据。
可能你要问,什么是“公开数据”呢?简而言之,就是网站上公开让用户浏览、获取的数据。
虽然数据是公开的,但是当某人或机构(如,搜索引擎)大量收集这些数据并因此获利时,也会让数据生产方——网站很不爽,由此而产生法律纠纷。比如,早些年Google因此而惹上官司。网站们看着搜索引擎
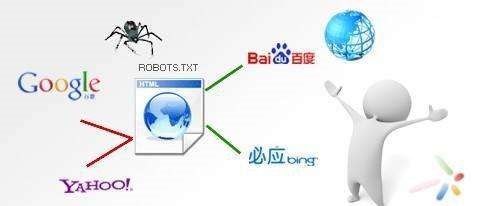
因为搜索引擎抓取自己的内容而获利不爽,但也因为搜索引擎带来的流量而高兴不已,于是就出现了网站主动进行搜索引擎优化(SEO, Search Engine Optimization),也就是告诉搜索引擎,我这里的内容好,
快来抓取吧!搜索引擎和网站的博弈,催生了一个君子协议: robots.txt。网站在自己的网站上放上这个文件,告诉爬虫哪些内容可以抓,哪些内容不可以抓;搜索引擎读取网站的robots.txt来知道自己的抓取范
围,同时也在访问网站时通过User-Agent来向网站表明自己的身份(这种表明也是君子协议,技术上很容易假扮他人),比如,Google的爬虫叫做Googlebot,百度的爬虫叫做Baiduspider。这样,二者和平共
处,互惠互利。

二、大数据时代的网络爬虫
时代在发展,数据变得越来越重要,“大数据”已经成为各行各业讨论的话题,人们对数据的渴望也变成贪婪,数据也就成了“石油”,爬虫也就成了“钻井机”。为了获取石油,人们使用钻井机;为了获取数据,人们
使用爬虫。为了获得数据,人们把互联网钻的是“千疮百孔”。哈哈,这里有些夸张。但人们对数据的获取,已经打破的君子协定,和网站们玩起了猫捉老鼠的游戏,展开了道高一尺魔高一丈的较量。为什么说是
较量呢?因为大量爬虫的行为会给网站带来网络带宽、服务器计算力等方面很大的压力,却几乎不带来任何利益。为了降低这种毫无利益的压力和避免自己的数据被他人集中收集,网站肯定要通过技术手段来限
制爬虫;另一方面,爬虫为了获取石油般的数据,就想方设法来突破这种限制。对于这种较量的理解,还是看活生生的例子来得更透彻。
你有没有花几十块钱让某个软件帮你抢火车票?
攻: 抢票爬虫会不断访问12306来获得火车票座位数据,并进而购买火车票;
防: 12306网站出了变态的认证码,人都经常识别错误。
各种秒杀让你很受伤!
攻: 研究网站的秒杀机制,提前写好爬虫,秒杀时刻,人快不过机器;
防: 有些秒杀的宣传作用很大就懒得防;有些秒杀机制复杂到你很难写出对应的爬虫;有些秒杀成功被发现作弊也会被取消。
爬虫变得越来越多,越来越肆无忌惮,网站也不得不使用各种技术手段来禁止或限制爬虫。这些手段大致包括:
使用账户保护数据,数据仅对登录用户可见;
数据多次异步加载;
限制IP访问频率,甚至封锁IP;
输入验证码以获得访问权限;
数据在服务器端加密,浏览器端解密;
……
而这些手段也是爬虫在技术实现中要解决和突破的问题。
三、网络爬虫的自我约束
看完上面“猫捉老鼠”的游戏的描述,小猿们不禁要问,网站和爬虫这种对抗较量会不会引起法律问题?
这是一个很好的问题,也是值得每个爬虫开发者思考的问题。
爬虫作为一种技术本身可能无所谓善恶,但是使用它的人就有善恶之分。如何使用爬虫,爬取的数据如何使用,都可能产生潜在的法律问题。作为技术开发的小猿们,都应该思考这个问题。无论何种目的,网络
爬虫都不能突破法律的底线,同时也有遵守一定的准则:
遵循robots.txt协议;
避免短时间高并发访问目标网站,避免干扰目标网站的正常运行;
不要抓取个人信息,比如手机通讯录等;
使用抓来的数据注意隐私保护,合法合规。
相关文章



 关闭
关闭