
IT安全运维| 数据防泄露DLP简介
2020-05-10 18:45 作者:艾锑无限 浏览量:
在企业IT运维中提到数据保护,大家可能常常想起文档,很少有人会关注文档中的内容,对数据的管理也比较单一,通常就是全加密、全授权,对文档的重要性不做区分,随着社会的发展,文档的格式越来越多,安全事件的不断爆发,使得人们对数据的关注度发生了变化,数据也分成了结构化数据和非结构化数据,更加的关注文档内容中的敏感信息,使用文档的应用有哪些,对不同类型的文档、含有不同内容的文档有区别的管理和存储。以前要管控数据,大多是强管控,直接全部隔离,或者全部加密,我们称之为囚笼、枷锁式的管控,在实际的数据生产、使用、流转中带来了很多不必要的麻烦,人们需要更加灵活的方式来处理数据,此时,智能化的数据安全管控应运而生,企业IT运维可以按照数据的重要程度有针对性的对数据进行控制。数据防泄漏的核心能力
什么是DLP呢?字面上翻译为“Data Leakage(Loss) Prevention数据泄露防护”,其核心能力就是内容识别,通过识别可以扩展到对数据的防控。内容识别应该具备的识别能力具体来说有关键字、正则表达式、文档指纹、确切数据源(数据库指纹)、支持向量机,针对于每一种能力又会衍伸出多种复合能力。DLP还应该具备防护能力,防护范围包括网络防护和终端防护。网络防护主要以审计、控制为主,终端防护除审计与控制能力外,还应包含传统的主机控制能力、加密和权限控制能力。总的来说,DLP其实就是一个综合体,最终实现的效果,应该是智能发现、智能加密、智能管控、智能审计,也是一整套的数据泄露防护方案。
数据防泄漏的组件构成
下图说明DLP的实体配置,以及不同模型在组织内的常驻位置。“网络 DLP”产品常驻于 DMZ 中,而其他产品则常驻于企业 LAN 或数据中心。 除了“终端 DLP”产品以外,所有其他产品都是以服务器为基础。
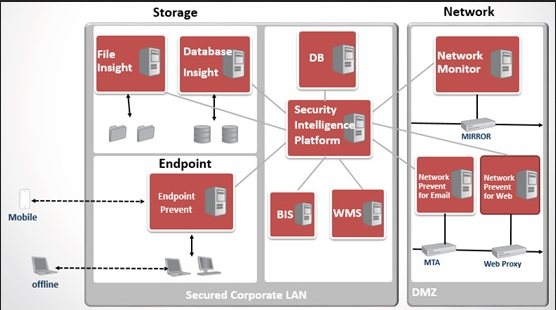
为了预防数据丢失,无论数据的存储、复制或传输位置在哪里,都必须准确地检测所有类型的机密数据。如果没有准确的检测,数据安全系统就会生成许多误报 (将并未违规的消息或文件标识为违规) 以及漏报 (未将违反策略的消息或文件标识为违规)。误报会大量耗费进行进一步调查和解决明显事故所需的时间和资源。漏报会掩盖安全漏洞,导致数据丢失、潜在财务损失、法律风险并有损组织声誉。因此需要准确的检测技术来做保障。为了确保最高的准确性,DLP 采用了三种基础检测技术和三种高级检测技术。
1、基础检测技术
基础检测技术中通常有三种方式,正则表达式检测(标示符)、关键字和关键字对检测、文档属性检测。基础检测方法采用常规的检测技术进行内容搜索和匹配,比较常见的都是正则表达式和关键字,此两种方法可以对明确的敏感信息内容进行检测;文档属性检测主要是针对文档的类型、文档的大小、文档的名称进行检测,其中文档的类型的检测是基于文件格式进行检测,不是简单的基于后缀名检测,对于修改后缀名的场景,文件类型检测可以准确的检测出被检测文件的类型,目前支持100多种标准的文件类型,并且可以通过自定义特征,去识别特殊的文件类型格式的文档。
2、高级检测技术
高级检测技术中也有三种方式,精确数据比对 (EDM)、指纹文档比对 (IDM)、向量分类比对 (SVM)。EDM 用于保护通常为结构化格式的数据,例如客户或员工数据库记录。IDM和SVM 用于保护非结构化的数据,例如 Microsoft Word 或 PowerPoint 文档。对于 EDM、IDM、SVM 而言,敏感数据会先由企业标识出来,然后再由DLP判别其特征,以进行精准的持续检测。判别特征的流程包括DLP访问和检索文本及数据、予以正规化,并使用不可逆的打乱方式进行保护。
DLP 检测是以实际的机密内容为基础,而非根据文件本身。因此,DLP不只能检测敏感数据的检索项或衍生项,而且能够标识文件格式与特征信息格式不同的敏感数据。例如,如果已经判别出机密 Microsoft Word 文档的特征,DLP就能够在相同的内容以 PDF 附件的方式通过电子邮件进行提交时,将其准确检测出来。
(1)精确数据比对
精确数据比对 (EDM) 可保护客户与员工的数据,以及其他通常存储在数据库中的结构化数据。例如,客户可能会撰写有关使用 EDM 检测的策略,以在消息中查找“名字”、“身份证号”、“银行帐号”或“电话号码”其中任意三项同时出现的情况,并将其映射至客户数据库中的记录。EDM 允许根据特定数据列中的任何数据栏组合进行检测;也就是在特定记录中检测 M 个字段中的 N 个字段。它能够在“值组”或指定的数据类型集上触发;例如,可接受名字与身份证号这两个字段的组合,但不接受名字与手机号这两个字段的组合。由于会针对每个数据存储格存储一个单独的打乱号码,因此只有来自单个列的映射数据才能触发正在查找不同数据组合的检测策略。例如,有个EDM 策略请求“名字+ 身份证号+手机号”的组合,则“张三”+“13333333333”“110001198107011533” 可触发此策略,但是即使 “李四”也位于同一数据库中,“李四”+“13333333333”“110001198107011533”也不能触发此策略。EDM 也支持相近逻辑以减少可能的误报情形。对于检测期间所处理的自由格式文本而言,单个特征列中所有数据各自的字数均必须在可配置的范围内,方可视为匹配项。例如,依默认,在检测到的电子邮件正文的文本中,“张三”+“13333333333”“110001198107011533”各自的字数必须在选定的范围内,才会出现匹配项。对于含有表式数据 (例如 Excel 电子表格) 的文本而言,单个特征列中所有数据都必须位于表式文本的同一行上,方可视为匹配项,以减少整体误报情形。
(2)指纹文档比对
“指纹文档比对”(IDM) 可确保准确检测以文档形式存储的非结构化数据,例如 Microsoft Word 与 PowerPoint 文件、PDF 文档、财务、并购文档,以及其他敏感或专有信息。IDM 会创建文档指纹特征,以检测原始文档的已检索部分、草稿或不同版本的受保护文档。IDM 首先要进行敏感文件的学习和训练,拿到敏感内容的文档时, IDM采用语义分析的技术进行分词,然后进行语义分析,提出来需要学习和训练的敏感信息文档的指纹模型,然后利用同样的方法对被测的文档或内容进行指纹抓取,将得到的指纹与训练的指纹进行比对,根据预设的相似度去确认被检测文档是否为敏感信息文档。这种方法可让 IDM 具备极高的准确率与较大的扩展性。
(3)向量机分类比对
支持向量机(Support Vector Machines)是由Vapnik等人于1995年提出来的。之后随着统计理论的发展,支持向量机也逐渐受到了各领域研究者的关注,在很短的时间就得到很广泛的应用。支持向量机是建立在统计学习理论的VC维理论和结构风险最小化原理基础上的,利用有限的样本所提供的信息对模型的复杂性和学习能力两者进行了寻求最佳的折中,以获得最好的泛化能力。SVM的基本思想是把训练数据非线性的映射到一个更高维的特征空间(Hilbert空间)中,在这个高维的特征空间中寻找到一个超平面使得正例和反例两者间的隔离边缘被最大化。SVM的出现有效的解决了传统的神经网络结果选择问题、局部极小值、过拟合等问题。并且在小样本、非线性、数据高维等机器学习问题中表现出很多令人注目的性质,被广泛地应用在模式识别,数据挖掘等领域。SVM比对算法适合那些具有微妙的特征或很难描述的数据,如财务报告和源代码等。使用过程中,先将文档按照内容细分化分类,每一类文档集合有属于本类的意义,经过SVM比对,确定被检测的文档属于哪一类,并取得此类文档的权限和策略。 同时,针对SVM的特点,可以进行终端或服务器上的文档按照分类含义进行分类数据发现。IDM和SVM的比对区别是,IDM将待检测文件的指纹和训练模型中的每一个文件进行指纹比对;而SVM是将待检测文件向量化,并归属到某一类训练集所建立的向量空间。
艾锑无限科技专业:IT外包、企业外包、北京IT外包、桌面运维、弱电工程、网站开发、wifi覆盖方案,网络外包,网络管理服务,网管外包,综合布线,服务器运维服务,中小企业it外包服务,服务器维保公司,硬件运维,网站运维服务
以上文章由北京艾锑无限科技发展有限公司整理
相关文章



 关闭
关闭